openEHR原型机制的技术概要
传统医疗数据模型的困境
在医疗信息化领域,常见的信息模型如 HL7 CDA(Clinical Document Architecture,临床文档架构)和 OMOP CDM(Common Data Model,通用数据模型)曾发挥着重要作用 。HL7 CDA 作为一种指定以交换为目的的临床文档结构和语意的文档标记标准,旨在实现在多个异构的系统中交换技术复杂度不同的具可读性的患者医疗文档。而 OMOP CDM 则是针对临床科研设计的通用数据模型,为不同来源的医疗数据提供了标准化的结构。
但医疗数据具有体量大、多态性、不完整性、冗余性及时效性等特点,这些传统模型在面对复杂的医疗数据时逐渐显露出诸多不足。随着医疗业务的不断拓展和变化,新的临床需求层出不穷,像基因检测、远程医疗监测等新的数据类型和业务场景不断涌现。这使得原本基于固定结构和规则设计的 HL7 CDA 和 OMOP CDM 难以快速适应,运维 IT 人员不得不花费大量时间和精力去调整和维护信息模型。
为了满足这些不断变化的需求,IT 人员需要频繁地修改数据库结构、调整数据接口等。每一次需求变更都可能涉及多个系统模块的调整,这不仅增加了出错的概率,还使得维护成本大幅上升。据相关数据统计,在一些大型医疗机构中,为了维护信息模型,每年在人力、物力和时间上的投入高达数百万甚至上千万元。
由于传统信息模型需要预先定义严格的数据结构和语义,为了尽量覆盖各种可能的医疗数据场景,模型中往往包含了大量冗余的数据元素。这些冗余数据不仅占据了宝贵的存储空间,还增加了数据处理的复杂性。在数据查询和分析时,系统需要处理大量无关数据,导致查询效率低下,响应时间变长。例如,在 OMOP CDM 中,为了满足不同临床研究的需求,可能会包含一些对于特定医疗机构或业务场景并不需要的数据字段,这些字段在数据存储和传输过程中造成了资源的浪费。
原型机制:破局之匙
在医疗数据模型构建的重重困境之下,原型机制应运而生,成为了打破僵局的关键所在。它是一种能够像信息模型动态添加临床语义的独特机制,为医疗数据的管理和利用开辟了新的路径。
与传统的面向对象分析机制(例如 UML,Unified Modeling Language 统一建模语言 )相比,原型机制具有显著的优势。UML 作为一种通用的可视化建模语言,在软件开发中常用于对系统进行分析、设计和文档化。它通过各种图形化的表示法,如类图、用例图、顺序图等,帮助开发团队清晰地理解系统的结构和行为。然而,在医疗数据模型建设中,UML 这种传统的面向对象分析机制存在一定的局限性。它往往更侧重于从技术角度出发,关注系统的功能和结构实现,对于临床领域的专业知识和语义理解相对不足。这就导致在实际应用中,临床专家和 IT 人员之间的沟通存在障碍,难以高效地协同工作。
而原型机制则很好地解决了这一问题。它能够充分发挥临床专家和 IT 人员的专业优势,实现两者的高效协同。临床专家可以凭借其丰富的医学知识和临床经验,深入理解医疗数据的内涵和业务需求,从而为原型的构建提供准确的临床语义指导。IT 人员则可以利用其技术专长,将临床专家提供的需求转化为具体的技术实现,通过对信息模型的操作和优化,确保原型的稳定性和可扩展性。在构建电子病历的数据模型时,临床专家可以明确指出病历中各个数据元素的临床意义和相互关系,如症状、诊断、治疗方案之间的关联等。IT 人员则根据这些需求,运用原型机制,在信息模型的基础上,通过 Archetypes 和 Templates 的构建,实现电子病历数据模型的快速搭建和灵活调整。
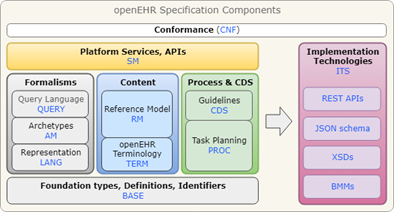
原型机制的三层架构剖析

信息模型(参考模型 RM)
在原型机制的架构体系中,信息模型,即 openEHR 所定义的参考模型(RM),处于基础且关键的地位。它就像是一座大厦的基石,为整个原型机制提供了最基本的数据语义定义。
参考模型 RM 对数据的基本类型进行了清晰界定,如整形、字符型、日期型等。这些基本数据类型是构建复杂医疗数据结构的基础元素,就如同建造房屋的砖块,每一块都有着明确的规格和用途。在记录患者的年龄时,会使用整形数据类型来准确表示;而记录患者的姓名,则采用字符型数据类型。除了基本数据类型,RM 还对数据的结构和关系进行了规范,定义了数据的存储方式、访问接口以及数据之间的关联规则。这些规范确保了数据在整个医疗信息系统中的一致性和可理解性,使得不同的系统和模块能够基于相同的标准进行数据交互和处理。
Archetypes:数据积木
Archetypes 由数据元构成标准数据集合,堪称整个原型机制中的 “数据积木” 。这些数据元是经过精心挑选和组织的,具有高度的复用性。它们就像一套标准化的积木组件,每一块都有着独特的形状和功能,但又可以相互组合,构建出各种各样的结构。
在医疗领域,不同的临床场景需要不同的数据组合方式。在构建电子病历中的诊断信息模块时,可以使用 Archetypes 中关于疾病诊断名称、诊断时间、诊断依据等数据元,将它们组合在一起,形成一个完整的诊断信息结构。这些数据积木的组合并非随意为之,而是基于严格的临床规范和业务逻辑。通过合理的组合,能够准确地表达各种临床概念和业务流程,满足不同医疗机构和医疗业务的需求。而且,由于 Archetypes 的复用性,一旦构建好一套通用的数据积木,就可以在多个项目和场景中重复使用,大大提高了开发效率,减少了重复劳动。
Templates:临床场景的定制
Templates 则是针对各种临床场景下的临床数据文档,由 Archetype 构成的内容模型。它就像是一个定制化的模板工厂,根据不同的临床需求,从 Archetypes 这个 “数据积木库” 中挑选合适的数据元,进行有针对性的组合和配置,从而生成满足特定临床场景需求的小型数据集。
在手术记录的模板构建中,Templates 会从 Archetypes 中选取手术名称、手术时间、手术医生、手术步骤、术中情况等相关的数据元,并根据手术记录的业务规范和格式要求,对这些数据元进行排列、约束和设置缺省值。这样生成的手术记录模板,既能够准确地记录手术过程中的关键信息,又符合临床业务的实际需求。Templates 的存在,使得医疗数据模型能够更加灵活地适应各种复杂多变的临床场景,提高了医疗信息系统的实用性和针对性。它就像是一把钥匙,能够打开不同临床场景下数据管理和应用的大门,让医疗数据真正服务于临床实践和医疗决策。
原型机制的规范体系
为了确保原型机制在医疗数据管理中能够高效、准确地运行,一套完善的规范体系必不可少。这套规范体系主要由以下 5 项构成:Archetype 标识系统、原型定义语言(ADL)、原型对象模型(AOM)、操作模板(OPT)、原型查询语言(AQL) ,每项规范都在原型机制中发挥着不可或缺的作用。
Archetype 标识系统
Archetype 标识系统为每个 Archetype 赋予了独一无二的身份标识,就如同每个人都有自己独特的身份证号码一样。这个标识系统是原型机制中数据识别和管理的基础,它确保了在复杂的医疗数据环境中,每个 Archetype 都能被准确地定位和引用。通过这个标识,不同的系统和模块可以清晰地识别和交互特定的 Archetype,避免了数据的混淆和错误使用。在医疗信息系统的集成过程中,各个子系统可以通过 Archetype 的标识来共享和交换数据,确保数据的一致性和准确性。
原型定义语言(ADL)
原型定义语言(ADL)是一种专门用于描述 Archetype 和 Template 的形式化语言,它是实现临床语义与技术实现之间沟通的桥梁。ADL 使用三种子语言:cADL (constraint form of ADL),即 ADL 的约束形式,用于对数据元素的取值范围、数据类型等进行严格约束,确保数据的准确性和规范性;ODIN (Object Data Instance Notation),对象数据实例表示法,用于描述数据的实例结构和关系,使数据的组织和呈现更加清晰;还有一阶谓词逻辑(FOPL)的一个版本,用于表达复杂的逻辑关系和业务规则。ADL 本身就像是一种 “胶水” 语法,将这些从属语法的块巧妙地连接起来,形成一个完整的、能够准确表达临床语义的整体。通过 ADL,临床专家可以将自己对医疗数据的理解和业务需求转化为具体的语言描述,IT 人员则可以依据这些描述进行系统的开发和实现。
原型对象模型(AOM)
原型对象模型(AOM)是 Archetype 在计算机系统中的一种抽象表示形式,它将 ADL 描述的 Archetype 转化为计算机能够理解和处理的对象模型。AOM 定义了 Archetype 的各个组成部分以及它们之间的关系,包括数据元素、约束条件、语义描述等。它就像是一个详细的蓝图,为 Archetype 在系统中的存储、传输和处理提供了统一的标准和规范。在医疗数据的存储过程中,AOM 可以确保数据按照规定的结构和格式进行存储,方便后续的查询和分析。同时,AOM 也为不同系统之间的 Archetype 交互提供了基础,使得不同的医疗信息系统能够基于相同的对象模型进行数据共享和协同工作。
操作模板(OPT)
操作模板(OPT)是基于 Archetype 和 AOM 生成的,用于指导具体业务操作的模板。它定义了在不同的临床场景下,如何对 Archetype 中的数据进行操作和处理,包括数据的录入、查询、更新、删除等操作。OPT 就像是一份详细的操作指南,为医疗信息系统的用户提供了清晰的操作流程和规范。在电子病历的录入过程中,OPT 可以指导医护人员按照规定的格式和要求录入患者的医疗信息,确保数据的完整性和准确性。同时,OPT 也可以根据不同的用户角色和权限,提供个性化的操作界面和功能,提高系统的易用性和安全性。
原型查询语言(AQL)
原型查询语言(AQL)是一种专门用于查询 Archetype 和基于 Archetype 构建的医疗数据的语言。它允许用户根据自己的需求,灵活地查询和获取所需的医疗数据。AQL 具有强大的查询功能,支持多种查询条件和逻辑运算符,可以实现复杂的数据筛选和分析。用户可以通过 AQL 查询特定患者的病历信息、统计某种疾病的发病率、分析药物的治疗效果等。AQL 的存在,使得医疗数据的价值能够得到充分的挖掘和利用,为医疗决策、科研分析等提供了有力的支持。
CKM 临床知识管理库:原型的宝库
在原型机制的生态体系中,CKM 临床知识管理库扮演着至关重要的角色,它是原型的集中存储和管理中心,为医疗数据模型的构建和应用提供了丰富的资源支持。
openEHR 基金会作为国际原型的治理机构,其托管的 CKM 临床知识管理库(https://ckm.openehr.org/ckm/ )堪称一座庞大的原型宝库。这里汇聚了来自全球各地的 Archetype,涵盖了各种常见和罕见的医疗场景,为医疗信息化的发展提供了坚实的基础。在这个知识管理库中,每一个 Archetype 都经过了严格的审核和验证,确保其准确性和可靠性。从常见疾病的诊断和治疗记录,到复杂手术的操作流程和术后护理信息,都能在其中找到对应的原型。
各个国家也纷纷建立了自己的 CKM,以满足本地医疗业务的特殊需求和规范。中国本地的临床知识管理库 HMC(http://hmc.openehr.org.cn/ ),结合了中国的医疗特色、临床实践经验以及相关政策法规,对 Archetype 进行了本地化的定制和优化。在中医诊疗领域,HMC 中收录了大量与中医辩证论治、中药方剂、针灸推拿等相关的 Archetype,这些原型充分体现了中医的理论体系和临床思维方式,为中医信息化的发展提供了有力支撑。
Archetype 的全局标识体系是其在 CKM 中准确管理和检索的关键。它主要有两种形式:使用 GUID(Globally Unique Identifier,全局唯一标识符)和人类可读 ID(HRID,Human Readable ID)。GUID 是一种由算法生成的 128 位数字标识符,具有极高的唯一性,几乎可以保证在全球范围内不会出现重复。它就像是一个独一无二的数字指纹,能够准确地标识每一个 Archetype。而 HRID 则是根据参考模型(RM)和 Archetype 两者的组合创建的,它更侧重于人类的可读性和理解性。HRID 通常包含了一些有意义的信息,如 Archetype 所属的领域、主题、版本等,使得用户可以通过阅读 HRID 快速了解 Archetype 的基本内容。在一个关于糖尿病诊断的 Archetype 中,HRID 可能会包含 “diabetes”(糖尿病)、“diagnosis”(诊断)等关键词,方便用户识别和查找。这种双重标识体系,既保证了 Archetype 在计算机系统中的准确识别和处理,又方便了用户在使用过程中的理解和管理。
原型定义语言(ADL)的奥秘
原型定义语言(ADL)在原型机制中扮演着至关重要的角色,它是精确描述 Archetype 和 Template 的关键工具,为医疗数据模型的构建提供了标准化和形式化的表达方式。
ADL 的源文件具有特定的格式,Archetype 和 Template 的 ADL 源文件通常以.adls 为后缀名,这种统一的文件格式便于对原型定义进行管理和识别,就像给所有的原型定义贴上了一个统一的 “标签”,方便系统进行读取和处理。操作模板文件则以.opt 为后缀名,这些文件在医疗数据的实际操作和应用中发挥着重要的指导作用。
ADL 之所以强大,在于它巧妙地融合了三种子语言:cADL、ODIN 和 FOPL 。cADL,即 ADL 的约束形式,它如同一位严格的 “把关人”,对数据元素的取值范围、数据类型等进行细致且严格的约束。在描述患者的年龄数据元时,cADL 可以明确规定其取值范围为 0 到 120(假设),并且数据类型为整形,这样就确保了在实际应用中,录入的年龄数据是准确和规范的,避免了因数据错误或不规范而导致的系统问题。
ODIN,也就是对象数据实例表示法,它专注于描述数据的实例结构和关系。在构建电子病历的过程中,ODIN 可以清晰地展示患者基本信息、诊断信息、治疗信息等各个数据实例之间的层次关系和关联方式,使数据的组织和呈现更加直观、清晰,方便医护人员和系统开发人员理解和操作。
FOPL 的一个版本则用于表达复杂的逻辑关系和业务规则。在医疗领域,存在着许多复杂的业务逻辑,如不同疾病的诊断标准、治疗方案的选择依据等。FOPL 可以通过逻辑表达式和规则定义,准确地表达这些复杂的业务逻辑。在判断某种疾病的诊断时,FOPL 可以根据患者的症状、检查结果、病史等多个因素,通过逻辑运算和规则匹配,得出准确的诊断结论。
ADL 本身就像是一种神奇的 “胶水” 语法,它将这三种子语言的块有机地连接起来。通过特定的语法规则和结构,ADL 能够将 cADL 定义的约束条件、ODIN 描述的数据实例结构以及 FOPL 表达的业务逻辑整合为一个完整的整体,从而准确地表达临床语义。这种整合使得原型定义不仅具备了严谨的规范性,还能够灵活地适应各种复杂的医疗业务场景,为医疗数据模型的构建提供了坚实的语言基础。
Template:功能与价值
在原型机制的体系中,Template 扮演着极为关键的角色,它就像是一位技艺精湛的工匠,能够将 Archetype 进行巧妙的组装和定制,从而构建出满足各种复杂临床需求的高效数据模型。
多个 Archetype 的组合
Template 拥有强大的组合能力,它可以像搭建积木一样,将任意数量的 Archetype 组合在一起。在构建一份综合性的患者病历数据模型时,Template 能够把描述患者基本信息的 Archetype、记录诊断信息的 Archetype、反映治疗过程的 Archetype 以及展现检验检查结果的 Archetype 等有机地整合起来。通过这种组合方式,Template 能够全面、系统地呈现患者的医疗状况,为医护人员提供完整的临床信息。这种组合并非简单的堆砌,而是基于严谨的临床逻辑和业务流程,确保各个 Archetype 之间的信息能够相互关联、相互印证,形成一个有机的整体。
删除不需要的数据元
在实际的临床应用中,并非 Archetype 中的所有数据元都对特定的业务场景有用。Template 具备精准筛选的能力,它能够从源 Archetype 中的大量数据元中挑选出真正需要的数据元,同时删除那些不必要的数据元。在一份针对门诊就诊记录的模板构建中,对于住院相关的一些数据元,如住院天数、病房号等,在门诊场景下是不需要的,Template 就可以将这些数据元剔除。这样做不仅能够减少数据的冗余,提高数据的存储和传输效率,还能使数据模型更加简洁明了,便于医护人员快速获取关键信息,提升工作效率。
对 Archetype 上数据元进行二次约束和设置缺省值
Template 还可以对 Archetype 中的数据元进行二次约束和设置缺省值,以满足特定的业务规则和数据质量要求。在记录患者的体温数据时,Archetype 中可能定义了体温的取值范围为一个较宽泛的区间,但在实际的临床应用中,对于正常人体体温,可能需要进一步将取值范围约束在更精确的区间,如 36℃ - 37.2℃ 。同时,Template 可以为一些常用的数据元设置缺省值,在记录患者的性别时,如果没有明确录入,Template 可以将缺省值设置为 “未知”,这样可以确保数据的完整性和一致性。通过二次约束和设置缺省值,Template 能够使数据模型更加符合实际的业务需求,提高数据的准确性和可靠性。
低代码与原型机制的融合
在当今数字化快速发展的时代,低代码开发已成为一种趋势,它以其高效、便捷的特点,为企业应用开发带来了新的变革。而原型机制在低代码开发领域中,更是发挥着独特且关键的作用,二者的融合为医疗信息系统的开发和优化开辟了新的道路。
Archetype 源文件作为原型机制的重要组成部分,在低代码开发流程中扮演着起始点的关键角色。它就像是一座蕴藏着丰富资源的宝藏,包含了大量经过精心定义和组织的数据元及临床语义描述。通过特定的编译工具和技术,Archetype 源文件能够被准确无误地编译成 Archetype 对象模型(AOM)。这个过程就如同将原始的矿石冶炼成精美的金属制品,AOM 作为 Archetype 在计算机系统中的抽象表示形式,具备了更易于计算机理解和处理的结构与属性。它清晰地定义了 Archetype 的各个组成部分,如数据元素的类型、约束条件、语义关联等,为后续的操作和应用奠定了坚实的基础。
AOM 不仅是 Archetype 的数字化呈现,更是支持动态生成操作模板(OPT)的核心支撑。基于 AOM 所提供的详细信息,系统能够根据不同的临床业务场景和需求,智能地生成相应的 OPT。在构建电子病历系统时,AOM 可以根据患者信息管理、诊断记录、治疗方案制定等不同的业务模块,动态生成与之对应的操作模板。这些模板明确地规定了在每个业务场景下,如何对 Archetype 中的数据进行具体的操作,如数据的录入方式、查询条件的设置、更新的规则以及删除的权限等。通过这种动态生成的方式,OPT 能够紧密贴合实际业务需求,为用户提供更加精准、高效的操作指导。
基于 OPT,开发人员可以快速生成上层应用,这一过程极大地体现了原型机制在低代码开发中的显著优势。传统的应用开发方式往往需要开发人员编写大量的代码,从底层的数据结构设计到上层的用户界面构建,每一个环节都需要耗费大量的时间和精力。而在原型机制与低代码开发融合的模式下,开发人员只需在 OPT 的基础上,通过简单的配置和少量的代码编写,即可快速搭建出满足业务需求的上层应用。利用低代码开发平台,开发人员可以通过拖拽、选择等可视化操作,将 OPT 中的各项操作和数据元素快速组合成一个完整的用户界面。同时,平台还会自动生成与这些操作相关的业务逻辑代码,大大减少了开发人员的工作量,提高了开发效率。
这种融合模式使得医疗信息系统的开发周期大幅缩短。以一个新的医疗业务功能开发为例,传统开发方式可能需要数月的时间,而采用原型机制与低代码开发相结合的方式,可能只需要数周甚至更短的时间。这不仅能够让医疗机构更快地响应市场变化和业务需求,还能降低开发成本,提高资源利用效率。此外,由于 OPT 是基于 AOM 动态生成的,能够紧密结合临床业务场景,因此生成的上层应用具有更好的用户体验和更高的实用性。医护人员在使用这些应用时,能够更加便捷地进行数据操作和业务处理,提高工作效率,减少人为错误。